Web Scraping Development Services
In data analytics since 1989, ScienceSoft builds ethical data scraping solutions that are compliant with data privacy regulations, website terms and conditions, and bandwidth fair use policies. Focusing on data accuracy and integrity, we enhance web scraping systems with analytics and reporting modules to help our clients drive accurate insights from the scraped data.

Web scraping development services are a way to get a solution that automatically collects, cleans, and structures data from company websites, ecommerce stores, online marketplaces, social media and review platforms, government databases, financial data exchanges, and other web sources.
Web Scraping Solutions to Support Your Business Needs
With practical experience in ecommerce, retail, real estate, advertising, media & entertainment, banking, lending, investment, insurance, and 20+ other industries, we choose case-specific data sources and scraping techniques to help our clients benefit from data that is tailored to their business needs.
![]()
Contact scraping
Extracting B2C and B2B contact information from company websites, business directories (e.g., Yellow Pages, Yelp), social media platforms, public record databases, and news articles.
![]()
Competitor and market monitoring
Tracking competitor prices, offerings, product availability, and promotions across websites and online marketplaces to build competitive pricing, marketing, stock management, and product development strategies.
![]()
Sentiment monitoring
Monitoring sentiment across review and social media platforms, news websites, forums, blogs, and other sources to help businesses manage brand reputation and optimize their products and services, and researchers — analyze public opinion or study social phenomena.
![]()
Data aggregation
Scraping data from credible sources (e.g., government databases, property listings, credit bureaus) to create aggregated platforms for market intelligence, customer and candidate background checks, portfolio management, or other business needs.
![]()
SEO and marketing analytics
Crawling search engines and competitors’ websites to get data on keyword SERP position, featured snippets keywords, backlink anchor text, image alt text, and other information needed to get insights into SEO strategies optimization and online visibility improvement.
![]()
AI and machine learning model training
Gathering high-volume, multi-source data to train ML/AI models, including those for natural language processing and image recognition. While raw scraped data can’t be used for meaningful AI training due to its chaotic nature, we can clean and consolidate it into accurate data sets.
Deployment options for web scraping tools
![]()
Cloud
Optimal for high-volume and high-speed data extraction due to the high scalability of cloud resources.
![]()
On-premises
Best for organizations that avoid third-party data hosting for compliance and security reasons.
Web Scraping Solution Services by ScienceSoft
![]()
Consulting on web scraping
We will provide you with a cost-benefit comparison of market-available web scraping software and advise you on the required aspects like improving data quality and accuracy and addressing legal limitations. We can also design an architecture for a one-of-a-kind solution that not only accumulates data but also helps drive insights for informed decision-making.
![]()
Web scraping solution implementation
We can set up and customize the chosen market-available web scraping software, develop custom software components (e.g., for data parsing, timeout handling), or build a fully custom solution with a warehouse, analytics dashboards, and reporting tools.
![]()
Web scraping solution support
We can help you reach and maintain the required velocity, availability, and performance of your solution and minimize the likelihood of errors and failures. We will also ensure that your system is compliant with changing regulations.
Why Our Clients Trust ScienceSoft
- Since 1989 in data analytics and AI development services.
- Since 2015 in business intelligence and data warehousing services.
- ISO 9001 and ISO 27001-certified to guarantee the quality of web scraping services and the security of our clients’ data.
- Established practices for scoping, cost estimation, risk mitigation, and other project management aspects to drive projects to their goals despite time and budget constraints.
- In-house PMO with 45 certified project managers (holding PSM, PMP, PMI-ACP certifications) to support large-scale and distributed projects.





Common Data Scraping Challenges and How We Solve Them
![]()
Low data quality
We set up data cleansing and normalization pipelines to eliminate data noise and errors (e.g., HTML tags mistakenly included in the data set, duplicate data entries, and outliers in product pricing data). We also enable data format standardization (e.g., for units of measurement, naming conventions, dates).
![]()
Poor data matching
We implement data matching mechanisms fitting for each specific data type. Exact matching is optimal for well-structured data like tabular product listings on ecommerce websites, while fuzzy matching is used for matching data that is prone to variations (e.g., names, addresses). In the case of highly nuanced data variations, we use machine learning for intelligent matching.
![]()
Legality of web scraping
We can design web scraping solutions in line with data privacy and IP protection regulations such as GDPR, CPPA, or DMCA. When using automated IP rotation and CAPTCHA-solving techniques to overcome scraping bans, we make sure to comply with the websites' terms and conditions and bandwidth fair usage policies. We also advise our clients on ethical web scraping and maintaining logs of scraping activities to support compliance audits.
![]()
Scraping dynamic content
We make sure the solution accurately scraps dynamic data like stock prices and news updates, data from carousel sliders, and infinite social media feeds. To do this, we analyze how website content is loaded and displayed and develop mechanisms for dynamic content detection (e.g., headless browsers, interception of proxies). We also implement mechanisms to simulate user interactions like scrolling pages, clicking buttons, and submitting forms.
![]()
Slow scraping speed at high data volumes
To enable fast scraping of high-volume data, we go for distributed scraping and parallel processing. We also optimize the code to improve the speed of the scraping scripts. For instance, batching HTTP requests helps minimize page reloads, preventing complete file parsing if only certain page elements are needed.
![]()
Data silos
Our web scraping solutions don't just amass terabytes of data. They clean, normalize, and match it to ensure it can be easily interpreted and used. Scraped data can be arranged in common file formats (e.g., PDF, CSV, JSON, XML) according to the required structure. We can also extend your web scraping software with data analytics functionality or integrate it with your BI & reporting system.
Sample Architecture of a Data Scraping Solution
Below, ScienceSoft’s solution architects provide a high-level architecture of a web scraping solution that is integrated with an analytics system to deliver insights based on the scraped data.
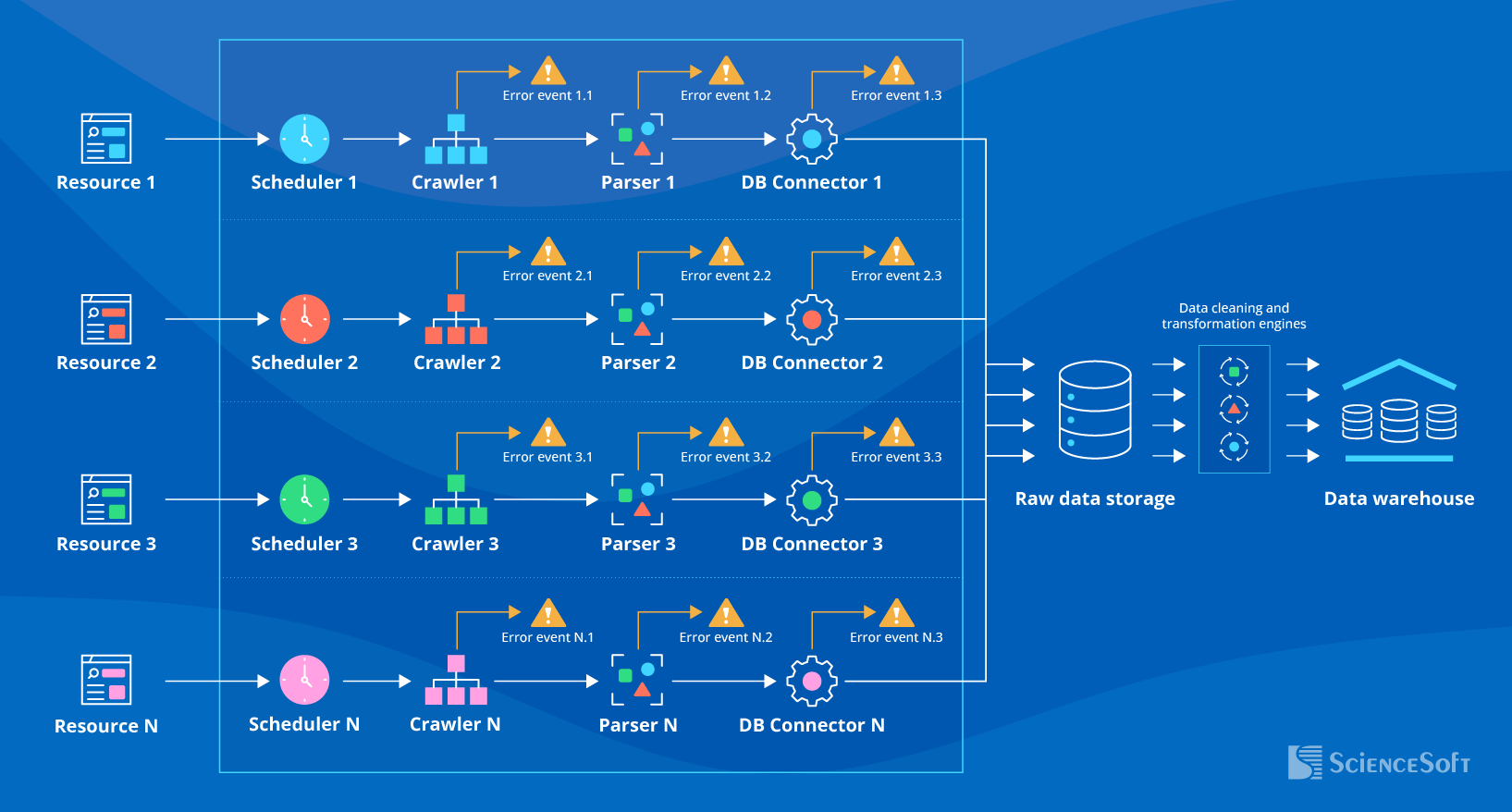
- A web scraper can extract data from a variety of sources, including company websites, social media platforms, online marketplaces, ecommerce stores, government databases, market data platforms, and more.
- A data crawler identifies and indexes pages within a website to map out its structure. A data parser then analyzes the information across the defined page elements and extracts the relevant data. This data is cleaned, deduplicated, and otherwise prepared to be organized in a structured format (e.g., a spreadsheet, a PDF file).
- Each web resource is scraped with specially coded crawlers and parsers that address the specifics of each page structure, layout, and content organization. For example, if a page contains structured HTML tables, the crawler will be coded to navigate the tables with the help of XPath or CSS selectors. For pages with infinite scroll features, it is optimal to have the crawler simulate scrolling, link clicking, and other user activity.
- Raw data storage (a.k.a. data lake) keeps data in its initial format until it is needed for analytics. ETL/ELT pipelines perform additional data cleansing and transformation to optimize data for the chosen data model (e.g., assigning keys to data on competitor names, pricing, and product SKUs to analyze how prices change for specific products).
- A data warehouse (DWH) stores data in a highly structured format that is ready for automated reporting and ad hoc business intelligence queries.
- Data orchestration automates the processes of collecting, transforming, and organizing data.
- The data governance and security framework ensures that data collection, transfer, sharing, and storage are in line with the required data protection regulations (e.g., GDPR, CPPA) and website terms and conditions.
Techs & Tools We Use to Build Reliable Web Scraping Solutions
Programming languages


Libraries and frameworks






![]()

Databases / data storages
SQL
![]()

![]()
![]()
![]()
![]()
NoSQL


![]()
![]()
![]()
Cloud storage
AWS






Azure
![]()
![]()

Google Cloud Platform


Data warehouse
![]()
![]()



![]()
Cloud services


![]()
Machine learning
Programming languages


![]()
Frameworks and libraries
![]()
![]()
![]()
![]()


![]()
![]()



![]()
Cloud services

![]()
![]()

Estimate the Cost of Your Web Scraping Solution

Web scraping development costs may range from $50,000 to $150,000, depending on solution complexity. The major cost factors include the type of web content to scrape (static or dynamic), the complexity of solution features, the need for data cleansing and analytics modules, and the solution deployment format.
Get a custom ballpark estimate for ScienceSoft’s data scraping services. It’s free and non-binding.
